
Linked Open Data From An Industry Perspective
We are in a internet data production era.
Every minute: Uber takes 45,787 trips, Spotify adds 13 new songs, we tweet 456,000 times, post 46,740 Instagram photos, publish 600 new page edits on Wikipedia, and Google performs 3.6 million searches1.
While the picture below confirms that “Data is the King” and the Internet produces an average of 2,657,700 gigabytes of Internet data every minute, Open Data is not “that much known of a relative”.

The Open Data Barometer, in their 4th edition report2, provides insight on the reasons behind this conclusion:
- o Nine out of ten government datasets are not open;
- o Government data is typically incomplete and of low quality;
- o Governments are not publishing the data needed to restore citizens’ trust.
Data Publishing methods like Linked Data and the technologies of the Semantic Web have been around for quite a while and have been hyped numerous times. In the meantime, a large number of enterprises (and even whole industries) have adopted semantic web technologies for several purposes.
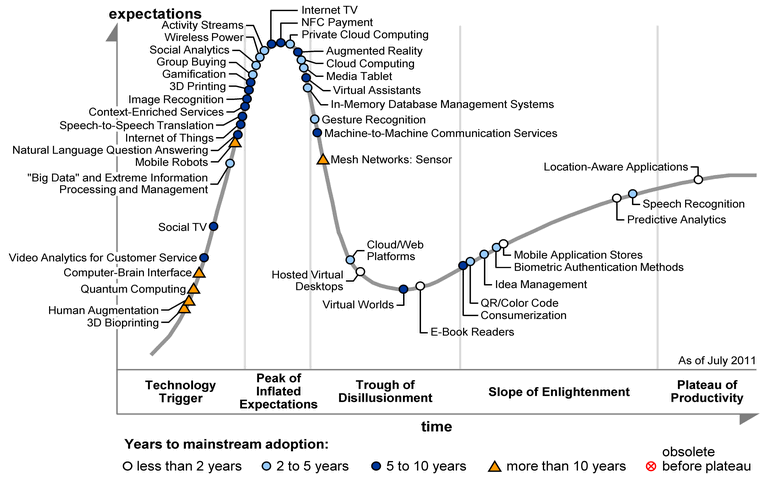
The focus now seems to shift more towards data analytics, data fusion and knowledge discovery for which, being a hype or not, Semantic technologies and Linked Data are needed. It does seem that the adoption of these technologies and methods is taking less time than what Gartner predicted in 2012 (see picture below) when he stated that the Semantic Web wouldn’t reach the plateau of productivity within the next 10 years.
Let’s now discuss how, at Cognizone, we have been implementing Semantic technologies and LOD solutions for the last 3 years. We want to share our experiences with you: the obstacles and challenges we faced, the solutions we reached and the lessons that we learned, whilst working with industrial-strength appliances of LOD and Semantic technologies.
Our adventure started by applying these technologies in the labour market area, via our involvement as the “technical right arm” behind ESCO3, a taxonomy of 2.942 Occupations and 13.485 skills and competencies translated in 26 languages that was published in July 2017. ESCO is built on a three pillars structure; the occupations, the skills and the qualifications.
The qualification pillar, left on the side for years, needed a push in order to be ready for the publication of ESCO. Cognizone actively participated in the elaboration, further development and publication of this pillar.
A few challenges laid ahead: a) The huge number of institutional stakeholders (the Member States themselves but also other intra MS contributors) involved in the qualification domain, b) the usage of old schemata to exchange information nationally or internationally and c) The verification of the trust of the information.
How did we overcome those challenges ?
The first step was to develop a thorough Linked Open Data schema (the Qualification Metadata Schema or QMS) that could build on previously used schemata to facilitate the exchange of qualification information between different stakeholders across Europe and the Learning Opportunities and Qualifications in Europe (LOQ) and ESCO portals. The schema had to support different exchange formats such as XML and RDF in order to cope with the different technology levels of the Member States.
The second step was to disseminate the content of the schema by organising workshops and visits to the national stakeholders that are involved in the process of publishing information about qualifications. The exercise allowed us to collect feedback not only from a group of domain experts, but from 20 different Member States. This brought the possibility to refine the schema up to a point where its completeness is no longer debatable. Finally, we developed a tool to store the published information about the qualifications. This tool standardise the qualification data, validate it against the QMS and add versioning information to it.
In parallel with our activities in ESCO, a 2nd Cognizone team was implementing solutions related to the Luxembourg Official Journal. The stakeholders behind the Journal had started up a course to dematerialise its legislative process by using Linked Open Data solutions.
The main barrier to overcome was the modelization of the legislation process. Domain experts were needed in order to define a tailor-made ontology representing these complex legislative relations. One also had to take into consideration exchange and reusability.
Once the ontology was developed, the time came to develop tools to support the capture and publishing of information related to Luxembourg legislative acts. We participated in the elaboration of two key web applications: Traités et Projets. A challenge we faced in this project was to maintain a coherence between the information shared between the different systems. We solved it by applying an architecture that allowed every platform to pull information from the same dataset and apply changes to it simultaneously.
What these experiences taught us can be summarized below :
- o The reuse of open standards was a key element of both projects. SKOS, DCAT, … are now mature and can support mission critical industrial strength applications.
- o Moving on from an old schema xml to linked open data ones, takes a lot of time; a transition period always be foreseen in order to support the evolution.
- o Businesses understand more and more the necessity of involving domain experts in the drafting of ontologies and schema.
- o Different sets of technologies need to be mixed with Linked Open Data technologies in order to allow more practitioners to apprehend its complexity. JSON seems to be a format that can help in that regard.
- o There are more and more business potentials for Linked Open Data companies!
As new projects and requests from businesses are coming in, we are quite positive about the future Linked Open Data technologies and solutions.
1. http://www.iflscience.com/technology/how-much-data-does-the-world-generate-every-minute/↩
Written by



Share